
Projekt Hintergrund - WebDatenBeschaffung an der FHNW
Dieser Blogpost basiert auf einer Arbeit im Modul WebDatenBeschaffung an der FHNW im Bachelorstudiengang Data Science. In diesem Modul geht es darum, effizient und gezielt Daten aus dem Internet zu sammeln und daraus spannende Erkenntnisse zu gewinnen. Im Rahmen einer kleinen Projektarbeit (Mini-Challenge) haben wir die Newsartikel aller Newssites der SRG gecrawlt und analysiert. Dieser Blogpost geht daher nicht auf die tieferen und komplexeren Themen der Datenbeschaffung und Softwareentwicklung ein, sondern soll einen Einblick in das Thema geben.
Was ist Web-Datenbeschaffung?
Web Data Mining, auch bekannt als Web Crawling oder Web Scraping, ist der Prozess der automatischen Extraktion von Informationen aus dem Internet. Es ist ein leistungsfähiges Werkzeug zur Sammlung und Analyse grosser Datenmengen, die sonst manuell nicht zugänglich wären.
In der modernen Zeit von ChatGPT und Bard werden solche Quellen immer wichtiger. Obwohl ChatGPT und Bard selbst nicht direkt auf öffentlichen Daten trainiert werden, basieren ihre Basismodelle GPT 3 & 4 sowie LaMDA und LaMDA 2 auf öffentlichen Daten. Der von Menschen produzierte Inhalt ist also immer noch die Basis für den Trainingsprozess dieser Modelle. Hinter solchen Modellen stehen auch Datensätze wie die von Common Crawl, die regelmässig Teile des Internets durchsuchen und die Daten öffentlich zur Verfügung stellen. Der Vortrag «State of GPT» bietet nicht nur einen spannenden Einblick in die Thematik der GPT, sondern zeigt auch, wie wichtig die Datenbeschaffung ist.
Diese Daten können jedoch nicht nur für KI-Modelle verwendet werden. Wir können Metadaten von Webseiten extrahieren und analysieren. Zum Beispiel die Kategorien, die Anzahl der Bilder oder die Komplexität der Sprache, der Artikel. Auf dieser Basis können wir Hypothesen aufstellen und diese mit den Daten überprüfen. Ein guter Vortrag, der uns zu diesem Projekt inspiriert hat, ist der 33c3 Vortrag von David Kriesel, der zeigt, was solche Metadaten alles über uns aussagen können.
Was sind Metadaten?
Metadaten sind Informationen über andere Daten. Sie beschreiben Eigenschaften, Attribute oder Merkmale von Daten, ohne den eigentlichen Inhalt zu beeinflussen. Metadaten können beispielsweise Informationen über den Ersteller, das Erstellungsdatum, die Länge oder die Komplexität eines Artikels beschreiben.
Während wir von Daten sprechen, die Informationen enthalten, sprechen wir von Metadaten, die Informationen über Informationen enthalten. Metadaten sind also Daten über Daten, können aber manchmal mehr aussagen als die Daten selbst.
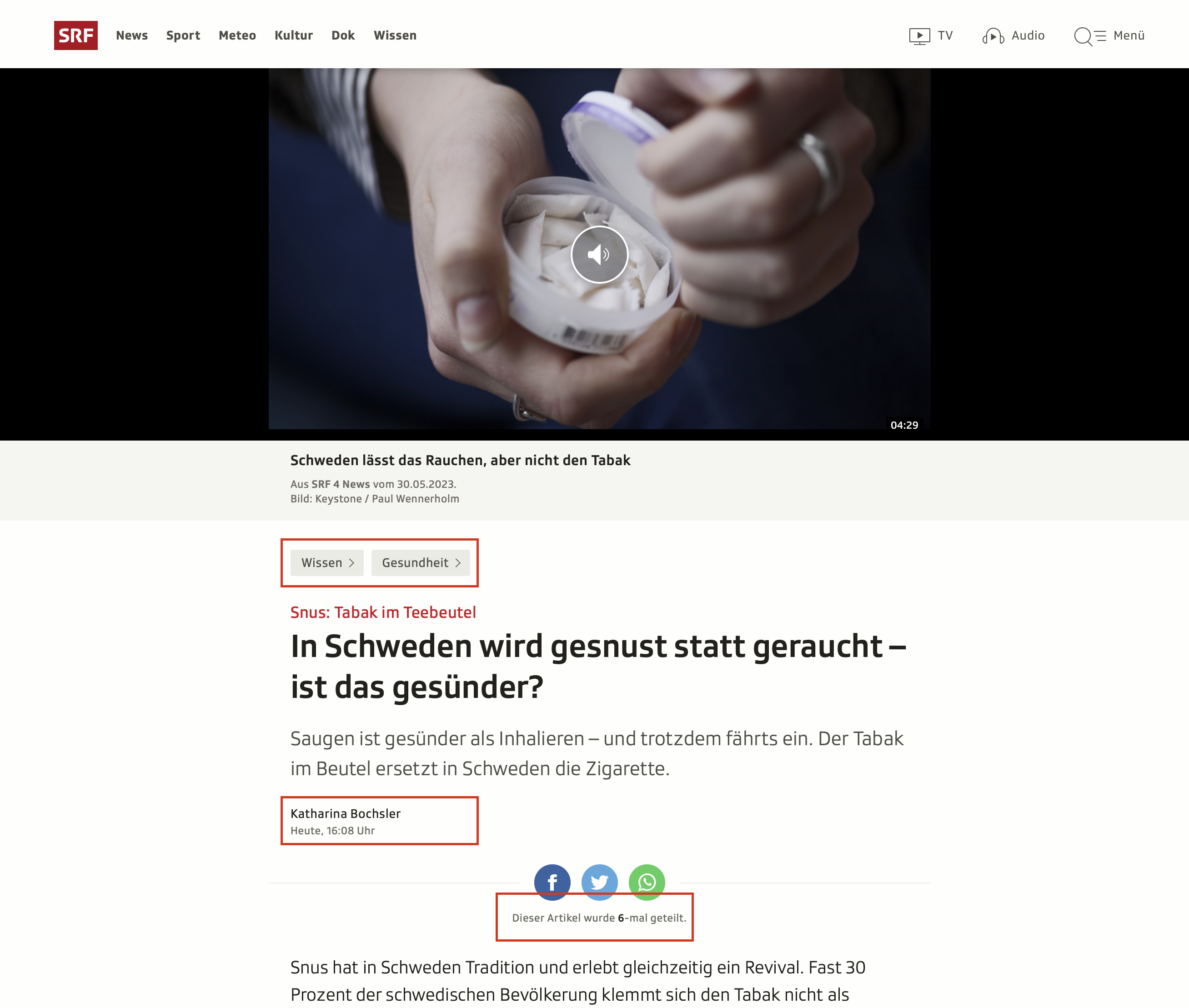 Darstellung der Metadaten auf der SRF-Beispielartikel-Website. Artikel Quelle: https://www.srf.ch/wissen/gesundheit/snus-tabak-im-teebeutel-in-schweden-wird-gesnust-statt-geraucht-ist-das-gesuender
Darstellung der Metadaten auf der SRF-Beispielartikel-Website. Artikel Quelle: https://www.srf.ch/wissen/gesundheit/snus-tabak-im-teebeutel-in-schweden-wird-gesnust-statt-geraucht-ist-das-gesuender
Daten vs. Metadaten vs. Rohdaten
Während wir den Artikeltext speichern und weitere Daten aus der Webseite und dem Text extrahieren können, sind die Rohdaten die Daten, die wir direkt von der Webseite erhalten. Diese liegen nicht immer in einem Format vor, das wir direkt weiterverwenden können. So sind Webseiten in der Regel in HTML geschrieben, das wir erst in ein Format umwandeln müssen, das wir weiterverarbeiten können.
Rohdaten sind geil!
- David Kriesel: 33c3 SpiegelMining
Wenn wir die Rohdaten speichern, können wir zu einem späteren Zeitpunkt frühere Artikel verarbeiten, falls wir etwas vergessen haben oder neue Erkenntnisse gewonnen haben. Für dieses Projekt speichern wir somit die gesamte HTML-Struktur der Website.
Wie können Daten aus Webseiten extrahiert werden?
Das Ziel der Webdatenerfassung ist es, den Inhalt der Website genau so zu erhalten, als ob ein echter Mensch die Website besuchen würde. Dazu verwenden wir die Python-Bibliothek selenium, die es uns ermöglicht, einen Browser zu steuern und mit ihm zu interagieren. Wir können eine Webseite öffnen, auf Links klicken, Formulare ausfüllen und vieles mehr in einem echten Browser, als wären wir ein Mensch.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://www.srf.ch/news")
Codeblock zur instanziierung eines Browsers und der Navigation zur SRF News Seite
Webdriver ist ein Protokoll, das von den gängigsten Browsern wie Firefox, Chrome, Edge, Safari und Opera unterstützt wird. Selenium bietet uns eine einfachere Schnittstelle zu diesem Protokoll, so dass wir es nicht jedes Mal neu implementieren müssen.
Selenium selbst ist jedoch davon abhängig, dass die notwendigen Browser und Treiber auf den Systemen installiert sind. Um sicherzustellen, dass der Treiber installiert ist und von Selenium richtig erkannt wird, verwenden wir das Paket webdriver_manager.
Der folgende Code stellt sicher, dass der Treiber korrekt installiert ist und instanziiert einen neuen Browser.
from selenium import webdriver
from selenium.webdriver.firefox.service import Service as FirefoxService
from webdriver_manager.firefox import GeckoDriverManager
driver = webdriver.Firefox(service=FirefoxService(GeckoDriverManager().install()))
Codeblock zur instanziierung eines Browsers mittels Treiber von webdriver_manager. Hinweis: Für Apple M1/M2 Chips gibt es derzeit keine ChromeDriver Pakete, daher wird hier Firefox verwendet
Cool! Jetzt können wir unsere erste Webseite besuchen. Dazu verwenden wir die *get Methode des Treibers und geben die URL der Webseite an.
driver.get("https://www.srf.ch/wissen/gesundheit/snus-tabak-im-teebeutel-in-schweden-wird-gesnust-statt-geraucht-ist-das-gesuender")
Codeblock zur Navigation zur SRF News Seite
Als Einstieg in Selenium empfehle ich die Selenium with Python Dokumentation oder die folgenden Youtube Videos.
XPATH
Die heutigen Webseiten sind nach dem HTML-Standard aufgebaut, welcher der XML-Struktur folgt. XPATH (XML Path Language) ist eine Abfragesprache, die es ermöglicht, Elemente in einem XML-Dokument zu finden.
Aber wo sind diese Elemente und wie finde ich sie? Dazu können wir die Entwicklerwerkzeuge des Browsers verwenden. In Firefox können wir diese mit F12 öffnen. In den Developer Tools können wir mit dem Button «Select an element in the page to inspect it» ein Element auswählen und die HTML-Struktur ansehen.
Nachfolgend können wir mit der Maus ein Element auswählen und die HTML-Struktur auf der rechten Seite ansehen.
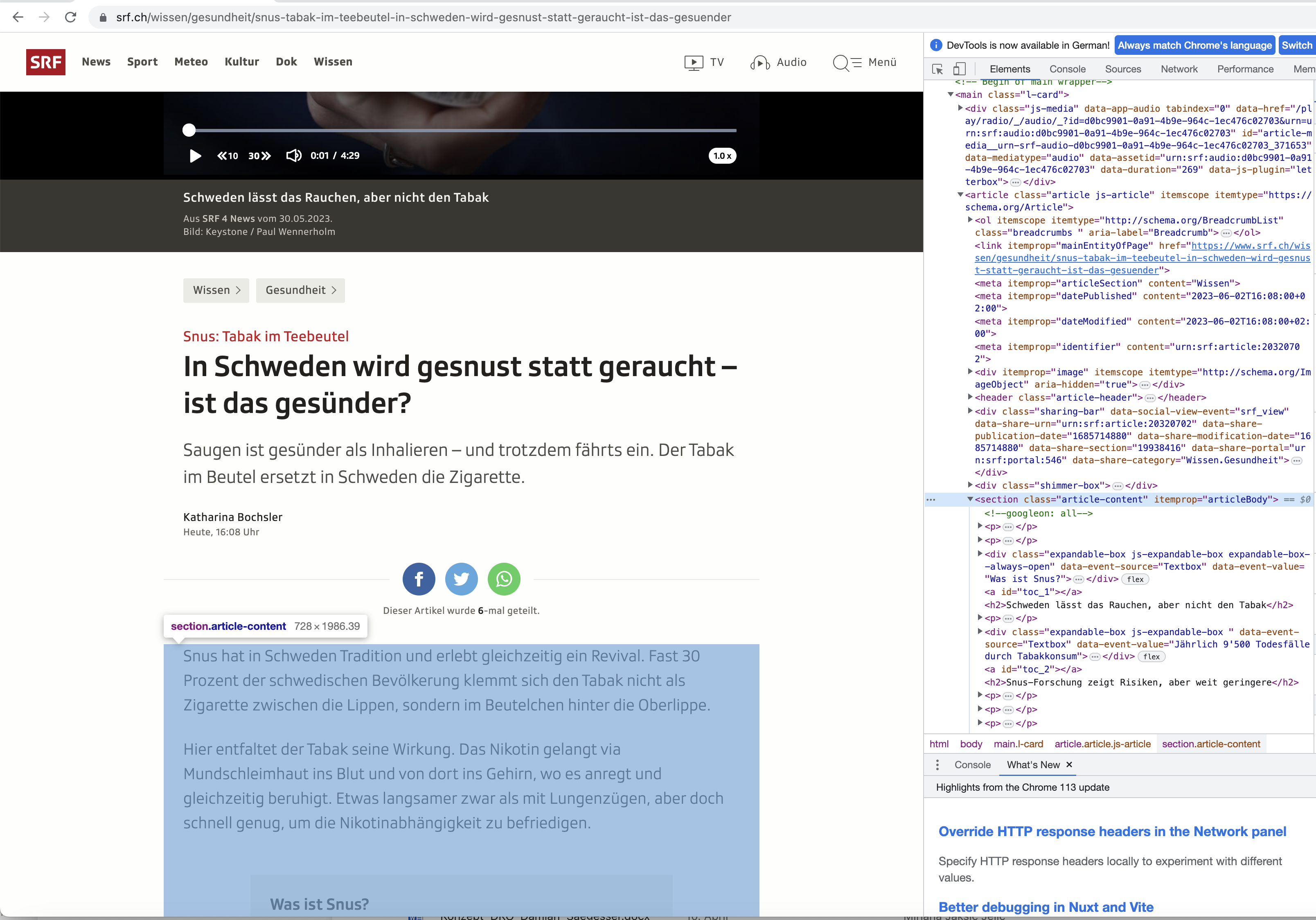 Darstellung der Entwicker-Tools mit verherhebung des Zentralen Artikel Content HTML Elements. Artikel Quelle: https://www.srf.ch/wissen/gesundheit/snus-tabak-im-teebeutel-in-schweden-wird-gesnust-statt-geraucht-ist-das-gesuender
Darstellung der Entwicker-Tools mit verherhebung des Zentralen Artikel Content HTML Elements. Artikel Quelle: https://www.srf.ch/wissen/gesundheit/snus-tabak-im-teebeutel-in-schweden-wird-gesnust-statt-geraucht-ist-das-gesuender
text = driver.find_element_by_xpath("//div[@class='article__body']")[0].text_content()
Codeblock zur extraktion des Textes aus dem HTML mittels XPATH
Mit dieser Abfrage suchen wir nach einem div Element mit der Klasse article__body und entnehmen diesem seinen Textinhalt. Wo sich das div Element befindet, spielt keine Rolle, da wir mit dem Operator // angeben, dass wir überall nach dem Element suchen wollen. Wenn sich die Webseite ändert, besteht die Chance, dass unser Code immer noch funktioniert.
Messung der Textkomplexität
Zur Bestimmung der Textkomplexität wurde die Python-Bibliothek textstat verwendet. Diese Bibliothek bietet eine Reihe von Funktionen, mit denen die Komplexität eines Textes bewertet werden kann. Wir haben uns für den «Flesch Reading Ease Score» (FRES) entschieden, der die Lesbarkeit eines Textes bewertet. Je niedriger der FRES-Wert, desto komplexer ist der Text.
Formel zur berechnung des Flesch Reading Ease Score
Die Funktion textstat.flesch_reading_ease(text) gibt den FRES-Wert für einen Text zurück. Um die Komplexität eines Artikels zu bestimmen, haben wir den FRES-Wert für jeden Absatz berechnet und den Durchschnittswert für den gesamten Artikel verwendet.
Wie können Texte verglichen werden?
Oft gibt es ähnliche oder sogar identische Artikel in verschiedenen Sprachen, aber die SRG bietet keinen einheitlichen Identifikator für diese Artikel. Um diese Artikel zu finden, müssen wir die Texte vergleichen und mit Hilfe eines Masses feststellen, ob es sich um den gleichen Artikel handelt. So können wir später die Artikel sprachübergreifend vergleichen und Hypothesen darüber aufstellen, wie sich die Sprache auf die Komplexität auswirkt, in welchen Landesteilen mehr über ein Thema berichtet wird oder wie das Thema in den Kommentaren aufgenommen wird.
Modelle wie Sakil/sentence_similarity_semantic_search sind darauf trainiert, nicht nur Texte 1:1 zu vergleichen, sondern auch semantische Ähnlichkeiten zu finden.

What is Sentence Similarity? - Hugging Face
Die Texte müssen jedoch in derselben Sprache sein. Ausgehend von der Website, von der wir den Text haben, können wir das Paket [translators] (https://pypi.org/project/translators/) verwenden, um den Text in eine andere Sprache zu übersetzen.
import translators.server as tss
translated_srf_text = tss.google(srf_text, from_language='de', to_language='en')
translated_rsi_text = tss.google(rsi_text, from_language='it', to_language='en')
Codeblock zur übersetzung des Textes mittels translators
Das Huggingface-Modell kann nun die beiden Texte vergleichen, geben wir mehrere Texte ein, so erhalten wir eine Liste der ähnlichsten Texte, die einer Zeile einer Cosine-Similarity-Matrix entspricht.
import requests
API_URL = "https://api-inference.huggingface.co/models/Sakil/sentence_similarity_semantic_search"
headers = {"Authorization": "Bearer <token>"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": {
"source_sentence": translated_srf_text,
"sentences": [
translated_rsi_text
]
},
})
Codeblock zur vergleichung der Texte mittels Huggingface Modell
Cosine-Similarity ist ein Mass für die Ähnlichkeit zwischen zwei Vektoren. In unserem Fall sind die Vektoren die Texte, die wir vergleichen wollen. Die Cosine-Similarity ist definiert als:
\[\cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{||\mathbf{A}|| ||\mathbf{B}||}\]Formel zur berechnung der Cosine-Similarity
Basierend auf dieser Ähnlichkeit und weiteren kriterien, wie dem Zeitabstand zwischen den Artikeln, können wir nun entscheiden, ob es sich um den gleichen Artikel handelt.
Unsere eigene Analyse
Nachdem wir die Daten gesammelt und die Textkomplexität berechnet haben, können wir nun unsere eigenen Analysen durchführen. Im Modul WDB hatten wir nur wenig Zeit für die Analyse, daher haben wir eine etwas experimentellere Datenexploration verwendet. Wir haben die sprachliche Komplexität für jeden Artikel berechnet und den Durchschnitt für jede Kategorie berechnet. Die Kategorien wurden von der SRG definiert. Wir haben auch die Anzahl der Artikel pro Kategorie gezählt, um zu sehen, wie viele Artikel pro Kategorie veröffentlicht werden.
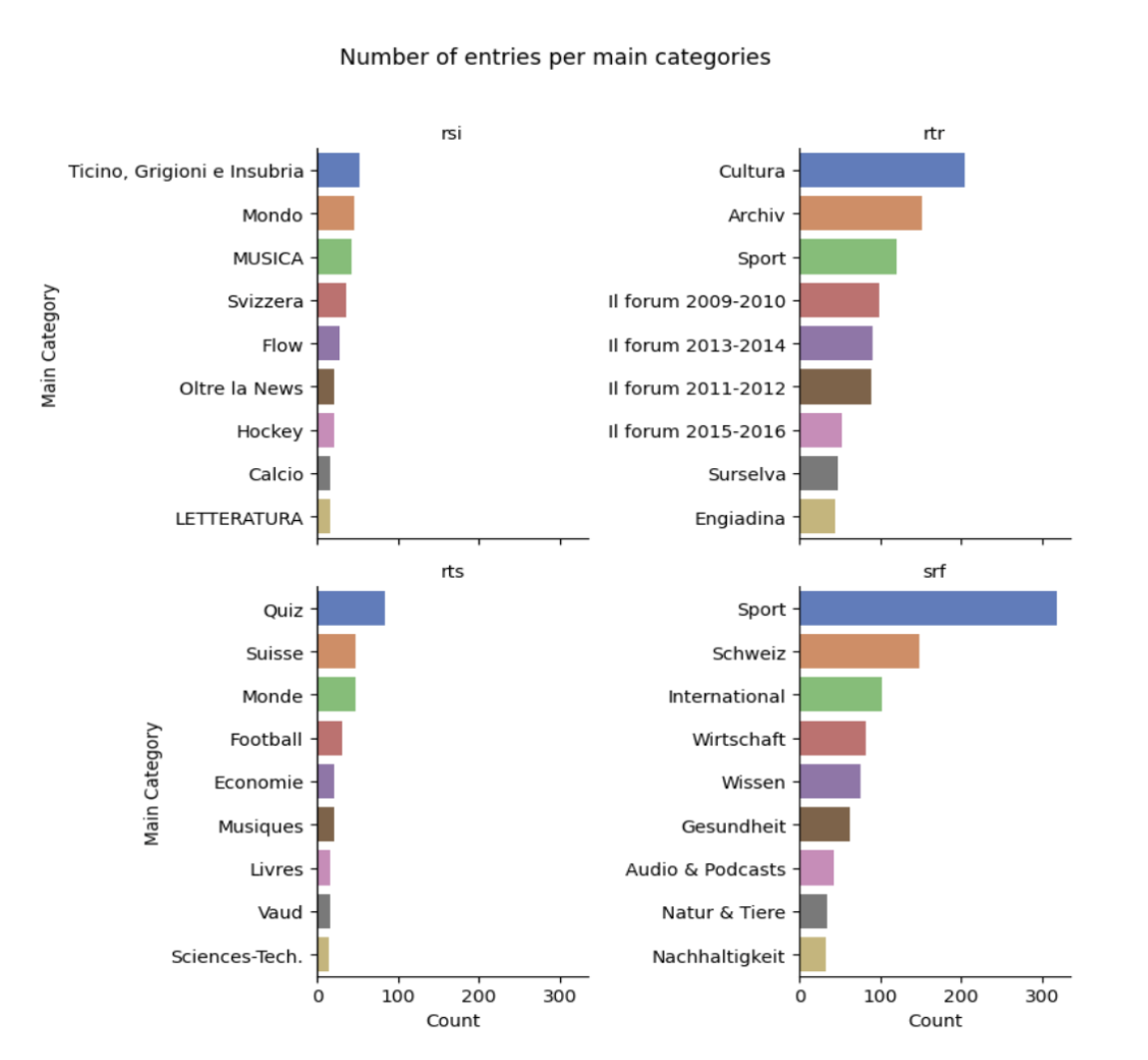 Darstellung der Anzahl Artikel pro Kategorie
Darstellung der Anzahl Artikel pro Kategorie
Wir können also feststellen, dass Kategorien wie Wirsichaft, Sport, Schweiz und Internationales die meisten Artikel auf den drei grössten Websites aufweisen, wobei die rätoromanische Schweiz vor allem auf ihre Kultur und den Sport ausgerichtet ist.
Nachdem wir festgestellt haben, dass sich die grössten Websites in Bezug auf die Beliebtheit der Kategorien stark überschneiden, haben wir die sprachliche Komplexität pro Kategorie verglichen. Auf diese Weise können wir die Komplexität der Texte in verschiedenen Sprachen innerhalb einer Kategorie vergleichen.
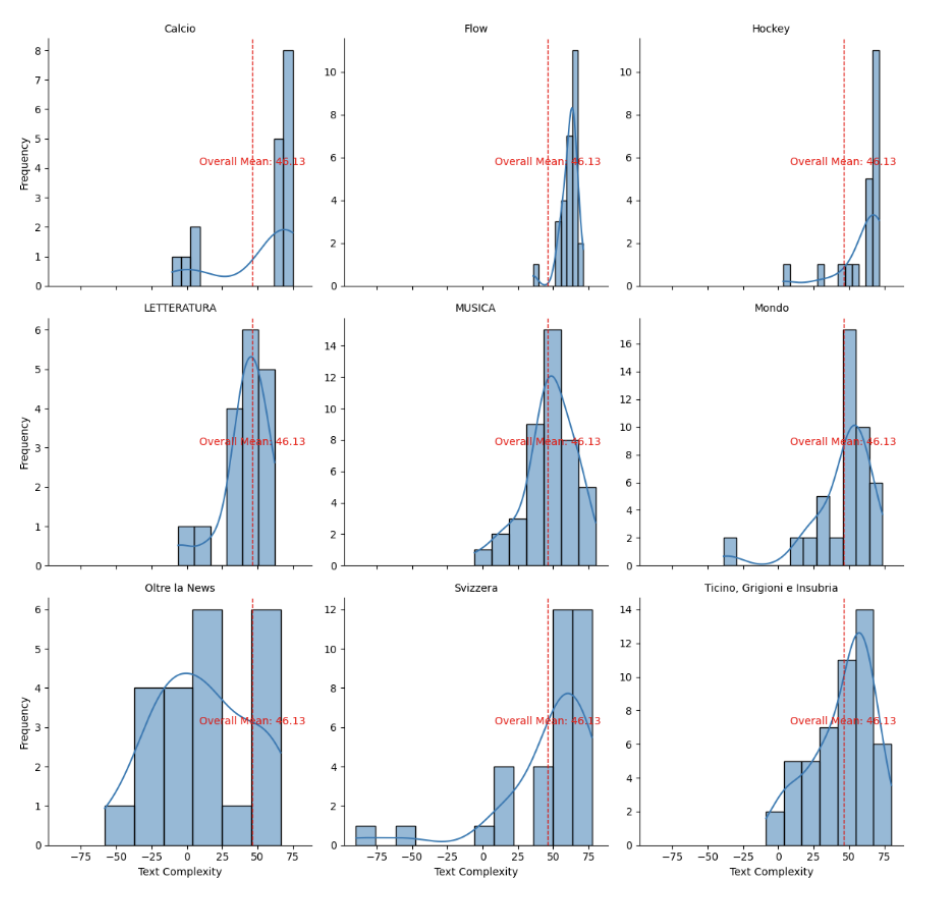
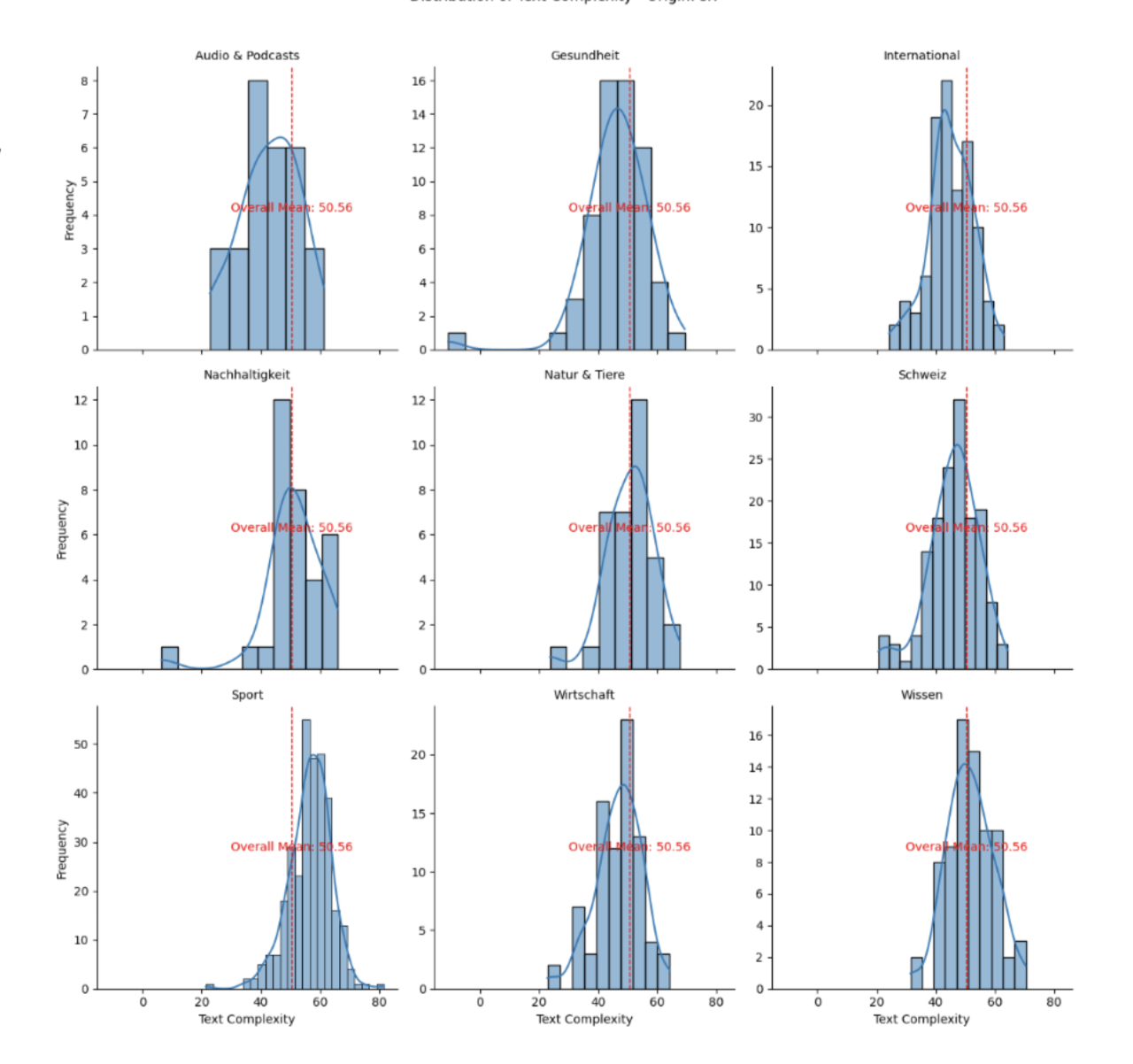
Vergleicht man die Kategorie «Schweiz» von SRF mit der Kategorie «Svizera» von RSI, stellt man fest, dass die sprachliche Komplexität der Artikel auf SRF geringer ist als auf RSI. Sind wir Deutschschweizer also einfach weniger fähig, komplexere Texte zu verstehen? ergo, sind wir dümmer?
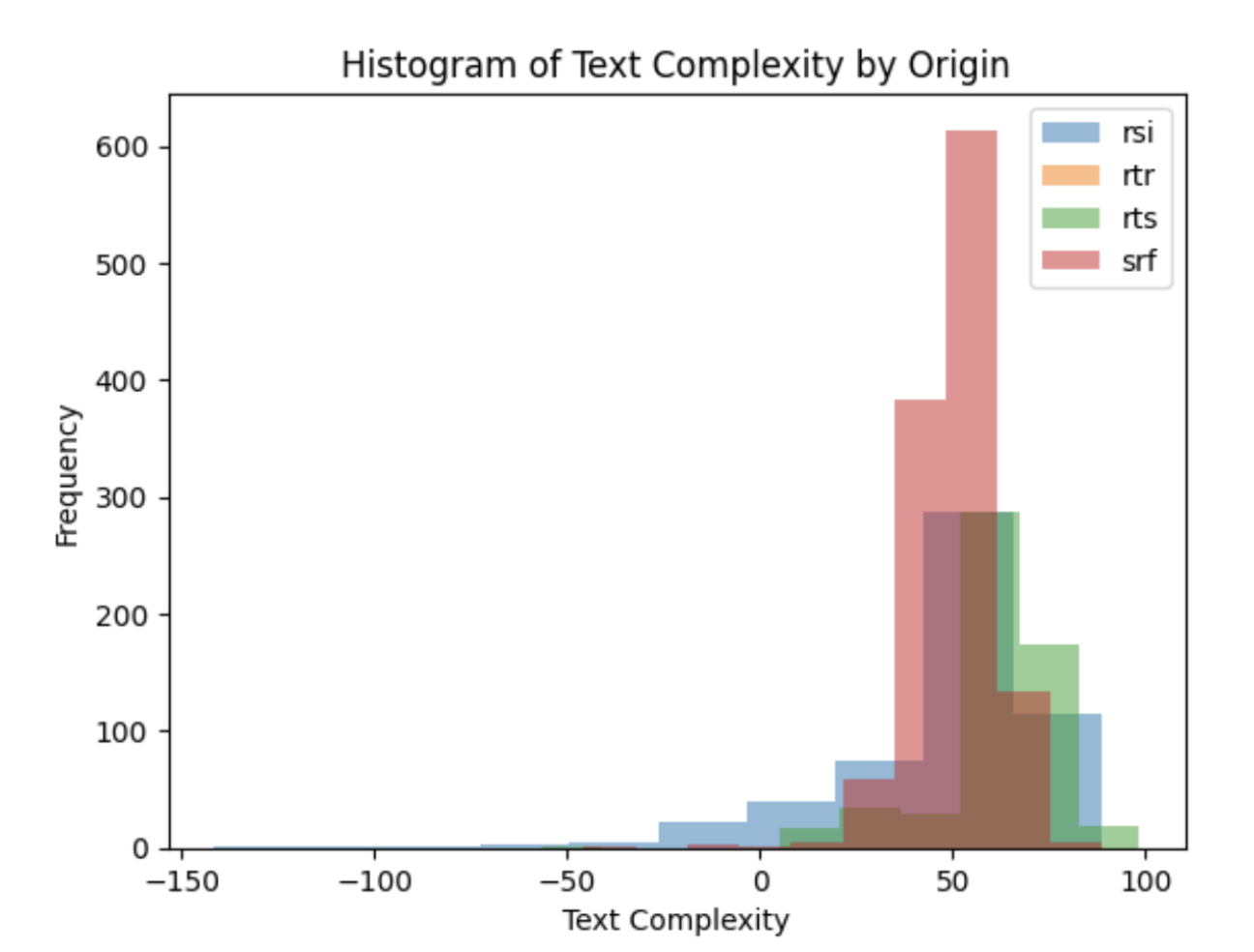 Graphischer vergleich der absoluten Verteilung an Sprachkomplexität pro Website
Graphischer vergleich der absoluten Verteilung an Sprachkomplexität pro Website
Der Vergleich der sprachlichen Komplexität aller Artikel zeigt, dass die mediane sprachliche Komplexität auf SRF etwas geringer ist als auf RSI. Dies kann auch damit zusammenhängen, dass das moderne Deutsch mit seinen Anglizismen einfachere Satzstrukturen aufweist als das Italienische.
Ethik der Webdatenbeschaffung
Webcrawling ist ein mächtiges Werkzeug, das uns tiefe Einblicke in die Welt der Online-Nachrichten geben kann. Es ist jedoch wichtig, dass wir uns der ethischen Implikationen des Einsatzes von Webcrawling bewusst sind. Aus diesem Grund haben wir uns entschieden, nur die Metadaten der Artikel zu erfassen und keine personenbezogenen Daten zu sammeln. Ausserdem haben wir die Anzahl der Anfragen an die Server der SRG begrenzt, um diese nicht zu überlasten. Unter normalen Umständen würde man sich an Konventionen halten, wie z.B. die Datei robots.txt, die die Anzahl der Anfragen pro Minute begrenzt und angibt, welche Seiten nicht gecrawlt werden sollen. In Anbetracht des Ziels und der schulischen Umstände wurde der Ertrag der Datenerhebung höher bewertet.

Robots.txt Introduction and Guide | Google Search Central | Documentation | Google for Developers
Zukünftige Schritte: Was kann noch gemacht werden?
Das Projekt ist weit davon entfernt, perfekt zu sein, und wir haben noch nicht genügend Daten gesammelt, um endgültige Schlussfolgerungen ziehen zu können. Es gibt noch viel zu tun, um die Daten zu verbessern und die Analysen zu verfeinern. Wir haben viele Ideen, wie wir dieses Projekt weiterentwickeln und welche Analysen wir durchführen könnten.
- Reichhaltigere Daten sammeln: Die Srf-Webseiten enthalten nicht nur Text, sondern auch Bilder, Audio, Video sowie externe Links und Einbettungen. Dies würde ein noch umfassenderes Bild der Website ergeben.
- Stimmungsanalyse der Texte: Während im aktuellen Projekt zusätzlich Kommentare extrahiert und Stimmungsanalysen durchgeführt werden, könnten auch die Artikel selbst analysiert werden. So könnte festgestellt werden, ob die Artikel positiv oder negativ sind und zu welchen Themen die Artikel in welche Richtung tendieren.
- Generierung von SRF-Nachrichten: Mit den Daten könnte ein Modell trainiert werden, das SRF-Nachrichten generiert. Ein eigenes GPT-Modell könnte so versuchen, mit minimalem Input eigene Artikel zu schreiben.
- Veränderungen auf Webseiten erkennen: Indem wir die Rohdaten speichern und die Artikel in regelmässigen Abständen überprüfen, können wir feststellen, ob sich der Inhalt eines Artikels verändert hat. So können wir feststellen, ob die SRG Artikel nachträglich verändert oder angepasst hat, ob Leserkommentare gelöscht wurden oder ob aufgrund neuer Ereignisse neue Kommentare geschrieben wurden.
Fazit
Web Data Mining und Textanalyse sind mächtige Werkzeuge, die uns tiefe Einblicke in die Welt der Online-Nachrichten geben können. Unsere Studie ist nur ein kleiner Teil dessen, was möglich ist.
In diesem Blogpost haben wir uns auf eine spannende Reise in die Welt der Webdatenbeschaffung begeben. Wir haben gesehen, wie wir Daten aus dem Internet extrahieren, Metadaten analysieren und die Komplexität von Texten bewerten können. Mit diesen Werkzeugen konnten wir interessante Einblicke in die sprachliche Komplexität von Schweizer Nachrichtenartikeln gewinnen. Es ist jedoch wichtig zu betonen, dass die ethischen Aspekte der Datenerhebung immer berücksichtigt werden müssen.
Unser Projekt ist noch nicht abgeschlossen und es gibt viele Möglichkeiten, es weiterzuentwickeln und zu verfeinern. Wir freuen uns darauf, unsere Erkenntnisse zu vertiefen und die Möglichkeiten der Datenerhebung im Internet voll auszuschöpfen.
Der gesamte Code hinter diesem Projekt kann auf der Gitlab-Instanz der FHNW eingesehen werden.

Christof Weickhardt / SRG Crawling · GitLab
Quellenverzeichnis
- Kincaid, J.P., Fishburne, R.P., Rogers, R.L., & Chissom, B.S. (1975). Derivation of new readability formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy enlisted personnel. Research Branch Report 8-75. Millington, TN: Naval Technical Training, U. S. Naval Air Station, Memphis, TN.
- Salton, G., Wong, A., & Yang, C.S. (1975). A Vector Space Model for Automatic Indexing. Communications of the ACM, 18(11), 613-620.
- Python Textstat Library. (2023). Retrieved from https://pypi.org/project/textstat/
- Beautiful Soup Documentation. (2023). Retrieved from https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- Selenium Documentation. (2023). Retrieved from https://selenium-python.readthedocs.io/
- Webdriver Manager Documentation. (2023). Retrieved from https://pypi.org/project/webdriver-manager/
- Common Crawl. (2023). Retrieved from https://commoncrawl.org
- Kriesel, D. (2016). SpiegelMining. Retrieved from https://www.youtube.com/watch?v=-YpwsdRKt8Q
- Kriesel, D. (2016). SpiegelMining Blog Serie. Retrieved from https://www.dkriesel.com/spiegelmining


{kind=link}